Daha Hafif Daha Hızlı: Derin Öğrenme Modellerinde Bilgi Distilasyonu
Daha Hafif Daha Hızlı: Derin Öğrenme Modellerinde Bilgi Distilasyonu

Günümüzde yapay zeka ve makine öğrenmesi yöntemleri kullanılarak çok başarılı projelere imza atılabilmektedir. Doğal afetleri tespit edebilen görüntü işleme modelleri, verilen cümlenin eş anlamlısını üretebilen doğal dil işleme modelleri ve bunlar gibi binlerce örnek etrafımıza baktığımızda kolayca fark edilebilir. Derin öğrenme(Deep Learning) modellerinin başarısının arkasında yazılımsal gelişmelerle birlikte yüksek performanslı ekran kartları gibi gelişmiş donanım parçalarının varlığı da çok önemli bir yere sahiptir. Peki biz başarılı bir şekilde çalışması için yüksek maliyetli ve performanslı donanım gerektiren bir modeli, daha kısıtlı imkanlarla aynı başarı oranında çalıştırabilir miyiz ? Bu sorunun cevabına hep birlikte bakalım.
Çözmesi gereken problemin büyüklüğüyle doğru orantılı bir şekilde zaman ve kaynak bakımından maliyetli olan derin öğrenme modellerini, çeşitli Model Sıkıştırma yöntemleri kullanarak, yüksek doğrulukta ve kısa çalışma zamanında gerçekleyebiliriz. Bu model sıkıştırma yöntemlerine bir göz atalım.
Pruning (Budama): Bu yöntemde amaç, modeldeki sıfıra yakın ağırlık ve aktivasyonların çıkarılarak daha küçük bir model elde edilmesidir. Böylece model, sonuca neredeyse hiç etki etmeyecek hesaplamalardan kurtarılmış olur.
Model Quantization (Model Niceleme): Model niceleme yöntemi, çıkarım için düşük hassasiyetli aritmetik işlemler yapmak temeline dayanan bir yöntemdir. Model niceleme yöntemini kullanmak isteyen biri, örneğin; 32 bitlik float sayılarla yapılan matematiksel işlemleri, 8 bitlik integer sayıları kullanarak yapabilir. Böylece büyük bir hesaplamasal yükten kurtulmuş olur. Ancak sayıların ifade edeceği küçük detayları kaybeder.
Knowledge Distillation (Bilgi Distilasyonu): Bilgi distilasyonu, önceden eğitilmiş ve öğretmen olarak seçilen bir modelin, öğrenci bir model ile eşleşmesine dayanan bir model sıkıştırma prosedürüdür.
Yukarıda üzerinden geçtiğimiz model sıkıştırma yöntemlerinden biri olan ve ayrıca bloğumuzun ana konusu olan Bilgi Distilasyonu’nu daha derinlemesine inceleyelim.
Bilgi Distilasyonundaki temel prensip daha önce de kısaca bahsettiğimiz üzere, daha geniş ve kompleks bir model olarak seçilen öğretmen modelin bilgisini, daha hafif ve küçük bir model olarak seçilen öğrenci modele aktarmasıdır. Bu bilgi aktarma işlemi için ilk olarak, önceden eğitilmiş (pre-trained) bir öğretmen modele ihtiyaç duyulmaktadır. Öğretmen modelin, çeşitli işlemlerden geçirilerek öğrenci modele özelliklerini aktarması sağlanır.
Nasıl Çalışır?
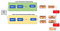

Softmax Function (Softmax Fonksiyonu): Çoklu sınıflandırma problemleri için kullanılır. Verilen her bir girdinin, bir sınıfa ait olma olasılığını gösteren [0,1] arası çıktılar üretmektedir. Hem öğretmen hem öğrenci modelleri eğitilirken kullanılır.
Soft Labels (Esnek Etiketler): Öğretmen model tarafından üretilen değerlerin “doğru” olarak kabul edilmesiyle ortaya çıkan veri etiketleme şeklidir. Esnek etiket olarak adlandırılmasının sebebi, öğretmen modelin doğru ve kesin bir sonuç verememe ihtimalinin bulunmasıdır.
Soft Predictions (Esnek Tahminler): Normal şartlarda [0,1] arasında değer üreten Softmax’ın, 1'den büyük kullanıldığı öğrenci modelinin çıktısıdır. Esnek tahminler, Softmax’ın olasılıkları yerine nihai Softmax’ın girdileri olan logitleri (0–1 arasında değer üreten bir olasılık fonksiyonu) kullanır.


Distillation Loss (Distilasyon Kaybı): Öğretmen model tarafından üretilen logitler ile küçük model tarafından üretilen logitler arasındaki kare farkının en aza indirilmesi için “Soft Predictions” kullanır. Distilasyon kaybında, öğretmen modelin softmax fonksiyonunun yüksek sıcaklık (parametre olarak verilen “temperature” değeri) ile eğitilmesiyle bilgi, distilasyon modeline aktarılır.
Hard Predictions (Keskin Tahminler): Öğrenci modelinde normal Softmax kullanıldığında elde edilen öğrenci modelinin çıktısıdır. Öğrenci modelinin distilasyon işlemine tabii tutulduktan sonra, esnek tahminlerden faydalanarak kendi tahminlerini oluşturduğu durumdur.


Ground Truth (Gerçek Sonuç): Bir fotoğrafta kedi olduğunu varsayalım. Elimizde bulunan öğretmen modeli doğru kabul ettiğimizde sonucun köpek çıkabilme ihtimali mevcuttur. Fakat gerçek doğru, fotoğrafın kesin bir şekilde kedi olduğunu söyler.
Student Loss (Öğrenci Doğru Tahmin Kaybı): Öğretmen modelin distilasyon kaybından (distillation loss) elde edilen sabitleştirilmiş sonuç ile gerçek sonuç arasındaki fark, öğrenci modelin bir girdiyi doğru tahmin etmedeki kaybını verir.
Kendi yarattığımız CNN modelini kullanarak bir uygulama örneği verelim:
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, BatchNormalization, Activation, MaxPooling2D
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import layers
from tensorflow.keras import activations
from tensorflow import kerasdef get_teacher_model(classes): model = Sequential(name='teacher') # 1 - Konvolüsyon katmanı
model.add(Conv2D(64, (3, 3), padding='same', input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) # 2. Konvolüsyon katmanı
model.add(Conv2D(128, (5, 5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25)) # 3. Konvolüsyon katman
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) # 4. Konvolüsyon katmanı
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25)) # Flattening
model.add(Flatten())# kısa yol : model.add(Dense(classes, activation='softmax'))
model.add(layers.Dense(classes))
model.add(layers.Activation(activations.softmax)) model.summary()
return model# get_teacher_model(10) -- method call


def get_student_model(classes): model = Sequential(name='student') # 1 - Konvolüsyon katmanı
model.add(Conv2D(16, (3, 3), padding='same', input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) # 2. Konvolüsyon katmanı
model.add(Conv2D(32, (5, 5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25)) # 3. Konvolüsyon katmanı
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) # Flattening
model.add(Flatten())# kısa yol : model.add(Dense(classes, activation='softmax'))
model.add(layers.Dense(classes))
model.add(layers.Activation(activations.softmax)) model.summary()
return model# get_student_model(10) -- method call


Bilgi Distilasyonu implementasyonu:
import tensorflow as tf
from tensorflow import keras
import OurModelNUM_CLASSES = 10 # verisetindeki sınıf sayısı
BATCH_SIZE = 64
EPOCH_TEACHER = 10 # öğretmen modelin eğitimindeki adım sayısı
EPOCH_STUDENT = 10 # öğrenci modelin eğitimindeki adım sayısıclass Distiller(keras.Model): def __init__(self, student, teacher):
super(Distiller, self).__init__()
self.teacher = teacher
self.student = student def compile(
self,
optimizer,
metrics,
student_loss_fn,
distillation_loss_fn,
alpha=0.1,
temperature=3,
):
- optimizer: Keras’ın, öğrenci ağırlıkları için kullanacağımız optimize fonksiyonu.
- metrics (metrikler): Modelin çalışmasını değerlendirmek için kullanılacak metrikler.
- student_loss_fn (öğrenci kayıp fonksiyonu): Öğrenci tahminleri ve temel gerçek arasındaki farkın kayıp fonksiyonu.
- distilasyon_loss_fn (distilasyon kayıp fonksiyonu): Esnek öğrenci tahminleri ile esnek öğretmen tahminleri arasındaki farkın kayıp fonksiyonu.
- alpha: student_loss_fn’ye göre ağırlık ve distilasyon_loss_fn’ye 1-alfa
- temperature (sıcaklık): Olasılık dağılımlarını yumuşatma oranı. Daha yüksek sıcaklık daha yumuşak dağılımlar sağlar.
super(Distiller, self).compile(optimizer=optimizer, metrics=metrics)
self.student_loss_fn = student_loss_fn
self.distillation_loss_fn = distillation_loss_fn
self.alpha = alpha
self.temperature = temperaturedef train_step(self, data):
# veriyi çıkar
x, y = data# öğretmenin geçişi - öğretmenin eğitilebilirliği kapatılır
teacher_predictions = self.teacher(x, training=False) with tf.GradientTape() as tape:
# öğrencinin geçişi - öğrencinin eğitilebilirliği açılır
student_predictions = self.student(x, training=True)# loss değerlerini hesapla
student_loss = self.student_loss_fn(y, student_predictions)
distillation_loss = self.distillation_loss_fn(
tf.nn.softmax(teacher_predictions / self.temperature, axis=1),
tf.nn.softmax(student_predictions / self.temperature, axis=1),
)
loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss# gradyanları hesapla
trainable_vars = self.student.trainable_variables
gradients = tape.gradient(loss, trainable_vars)# ağırlıkları güncelle
self.optimizer.apply_gradients(zip(gradients, trainable_vars))# 'compile()' içinde yapılandırılan metrikleri güncelle.
self.compiled_metrics.update_state(y, student_predictions)# performans özetini döndür
results = {m.name: m.result() for m in self.metrics}
results.update(
{"student_loss": student_loss, "distillation_loss": distillation_loss}
)
return resultsdef test_step(self, data):
# veriyi çıkar
x, y = data# Tahminleri yap
y_prediction = self.student(x, training=False)# loss değerini hesapla
student_loss = self.student_loss_fn(y, y_prediction)# metrikleri güncelle
self.compiled_metrics.update_state(y, y_prediction)# performans özetini döndür
results = {m.name: m.result() for m in self.metrics}
results.update({"student_loss": student_loss})
return results
Modellerimizi “train” ve “test” etme işlemleri için kullanacağımız veri kümesi, CIFAR10 olarak belirlendi.
teacher = OurModel.get_teacher_model(NUM_CLASSES)teacher.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)student = OurModel.get_student_model(NUM_CLASSES)
student_scratch = keras.models.clone_model(student)(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
Verinin normalize edilmesi ve öğretmen modelin eğitilmesi :
# -----------------Verinin Normalize Edilmesi--------------------# (görüntü sayısı, genişliği, yüksekliği)
print("Shape :", x_train.shape)# Görüntüleri [0-1] arasında normalize et
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0# Öğretmen modeli eğit ve değerlendir
teacher.fit(x_train, y_train, epochs=EPOCH_TEACHER, batch_size=BATCH_SIZE)
teacher.evaluate(x_test, y_test)
print('Teacher Trained!!!')


Distiller modelin, öğretmen ve öğrenci modelleri seçilerek belirlenmesi :
distiller = Distiller(student=student, teacher=teacher)distiller.compile(
optimizer=keras.optimizers.Adam(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
student_loss_fn=keras.losses.SparseCategoricalCrossentropy(from_logits=False),
distillation_loss_fn=keras.losses.KLDivergence(),
alpha=0.1,
temperature=10,
) distillation_loss_fn=keras.losses.KLDivergence(),
alpha=0.1,
temperature=10,
)
Bilgi distilasyonu — Distiller modelin eğitilmesi
# Distilasyon
distiller.fit(x_train, y_train, epochs=EPOCH_STUDENT, batch_size=BATCH_SIZE)# Distilasyon modeli test veriseti üzerinde değerlendirme
distiller.evaluate(x_test, y_test)
print('Distiller Trained!!!')


Öğrenci modelin karşılaştırma için sıfırdan eğitilmesi :
# -----------------Öğrenci Modelin Sıfırdan Eğitilmesi--------------student_scratch.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)# Öğrenci modeli sıfırdan eğit ve değerlendir
student_scratch.fit(x_train, y_train, epochs=EPOCH_STUDENT, batch_size=BATCH_SIZE)
student_scratch.evaluate(x_test, y_test)
print('Student Scratch Trained!!!')


Yukarıda Keras’ın önerilerine[3] dayanarak yaptığımız implementasyonu ve sonuçlarını görebilirsiniz. CIFAR-10 veriseti kullanarak eğittiğimiz öğretmen modelin ve bu öğretmen modele distilasyon uygulayarak elde ettiğimiz distiller modelin loss değerleri birbirlerine yakın olmakla birlikte, öğrenci modelin kendisini, sıfırdan eğittiğimizde elde ettiğimiz loss değerinin, diğer loss değerlerinden yüksek olduğunu gözlemleyebiliriz.
Böylece daha hafif bir modelde normal şartlarda elde edilmesi mümkün görünmeyen başarı oranları elde edilebilmektedir. Bunlarla birlikte, çözülmesi gereken problemin lineerliği azaldıkça bilgi distilasyonunun daha fazla fayda vereceğini öngörebiliriz.
Okuduğunuz için teşekkürler!
&Kaynakça
[2] : https://medium.com/analytics-vidhya/knowledge-distillation-in-a-deep-neural-network-c9dd59aff89b
[3] : https://keras.io/examples/vision/knowledge_distillation
Kapak Resmi : Anton Khrupin/Shutterstock.com



Yorumlar
Yorum Gönder